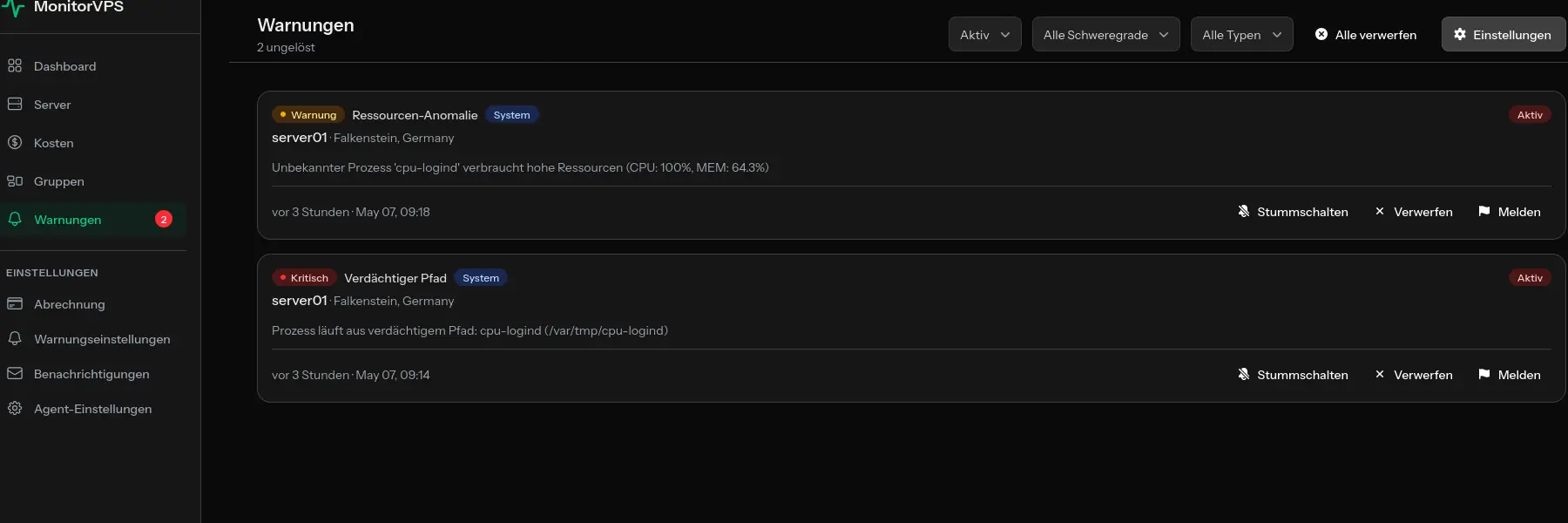
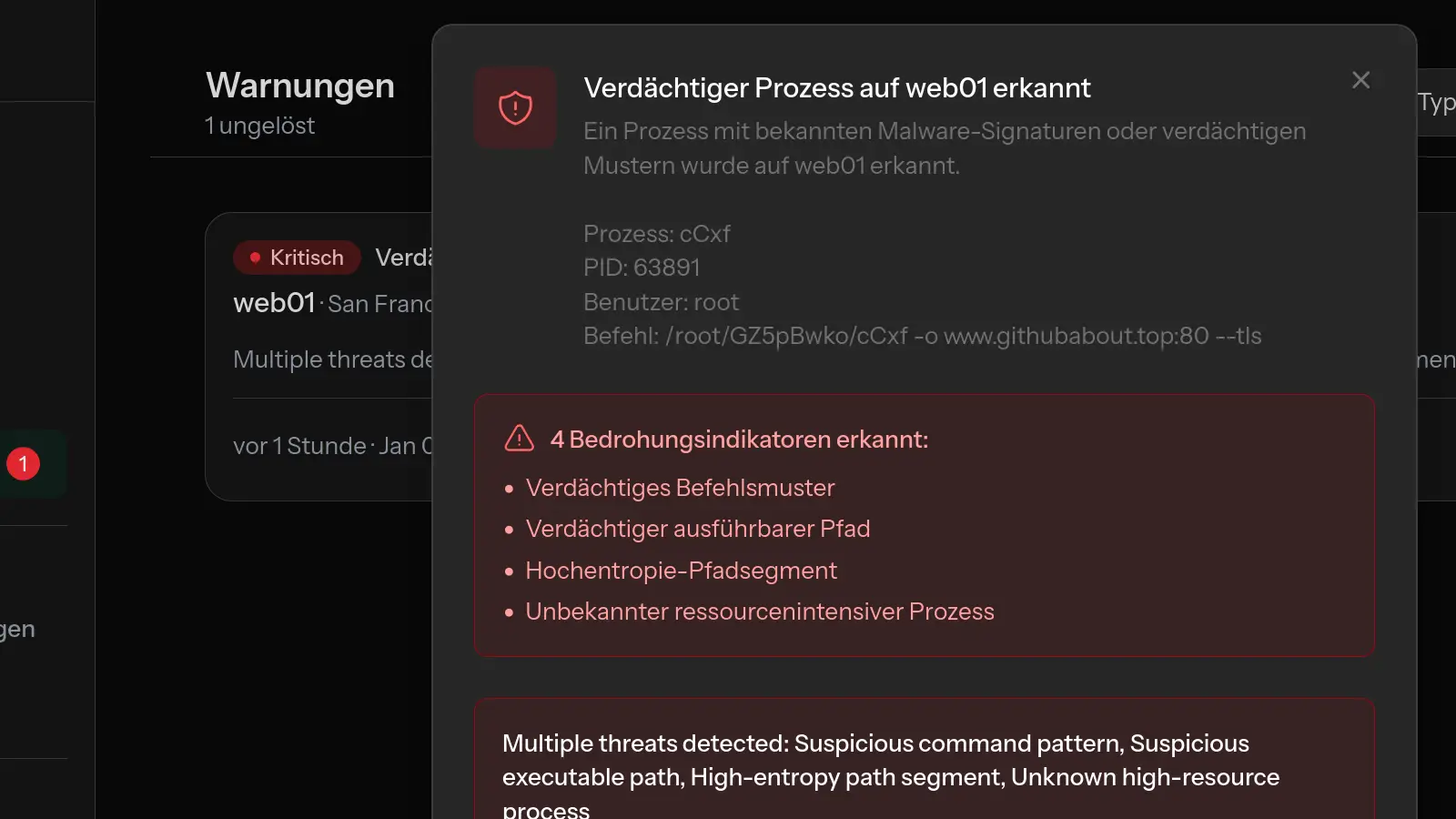
Diagnose häufiger VPS-Serverprobleme
Ein praktischer Leitfaden zur Fehlerbehebung bei VPS-Serverproblemen. Lernen Sie, Leistungsengpässe systematisch zu diagnostizieren und zu beheben.
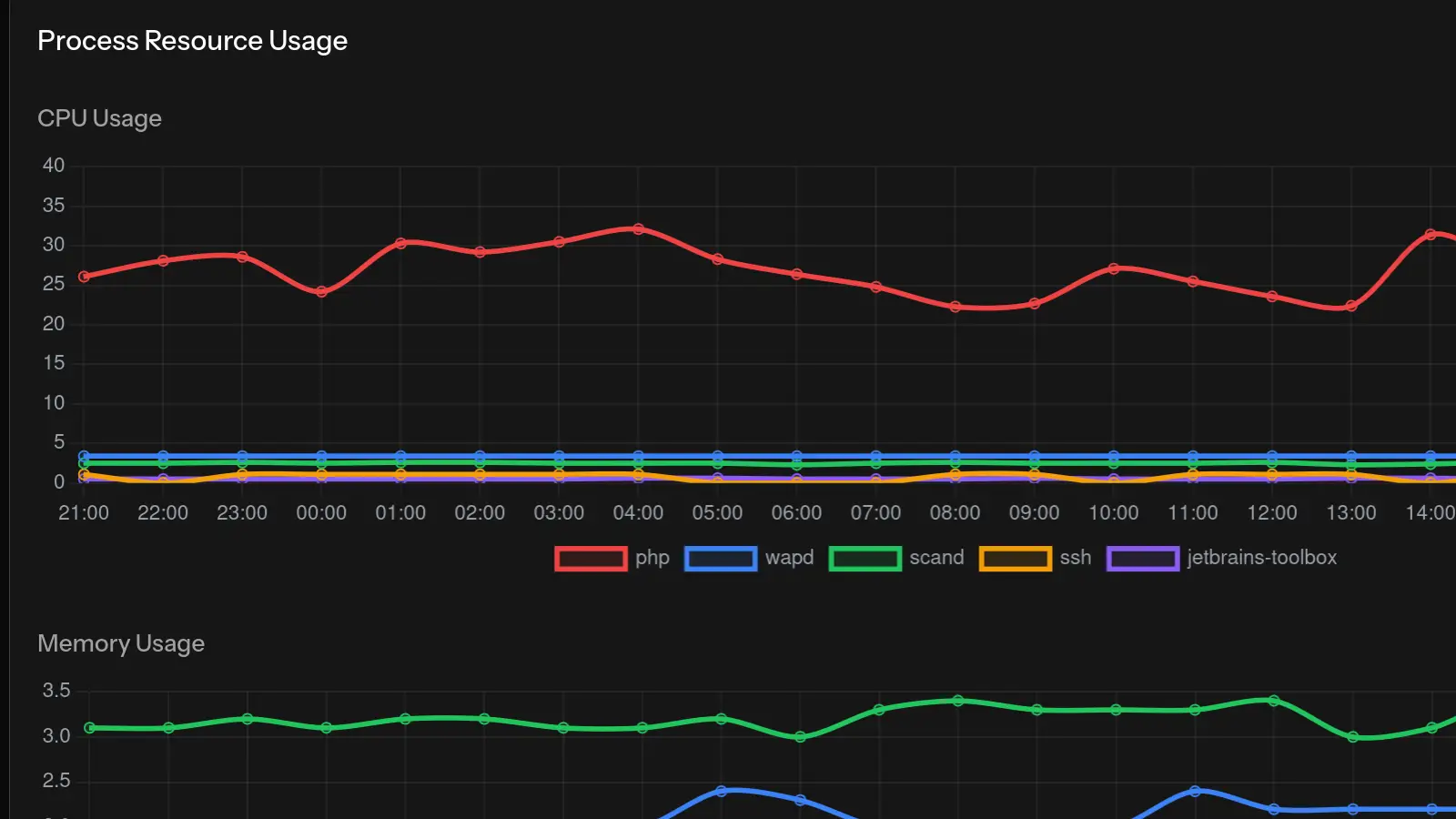
Die Diagnose von VPS-Serverproblemen umfasst die systematische Überprüfung der Ressourcennutzung (CPU, Speicher, Festplatte), die Analyse laufender Prozesse, die Überprüfung von Protokollen und die Verwendung von Überwachungstools zur Identifizierung von Mustern. Die meisten Serverprobleme fallen in einige häufige Kategorien, die mit dem richtigen Ansatz schnell identifiziert werden können.
Common VPS Server Problems and Their Symptoms
Bevor wir in die Diagnose eintauchen, hilft das Verständnis häufiger Problemmuster, Probleme schneller zu identifizieren:
Hohe CPU-Auslastung
- Symptome: Langsame Antwortzeiten, Timeout-Fehler, hoher Load Average
- Häufige Ursachen: Außer Kontrolle geratene Prozesse, Traffic-Spitzen, ineffizienter Code, Malware
Speichererschöpfung
- Symptome: Abstürzende Anwendungen, OOM Killer beendet Prozesse, Swap-Nutzungsspitzen
- Häufige Ursachen: Speicherlecks, unzureichendes RAM, zu viele gleichzeitige Verbindungen
Festplattenprobleme
- Symptome: Schreibfehler, Datenbankfehler, Anwendungsabstürze, Fehler bei der Protokollrotation
- Häufige Ursachen: Wachstum der Protokolldateien, nicht gelöschter Cache, Datenbank-Bloat, Datei-Uploads
Nicht reagierender Server
- Symptome: SSH-Timeout, fehlgeschlagene Web-Anfragen, Dienste reagieren nicht
- Häufige Ursachen: Ressourcenerschöpfung, Netzwerkprobleme, Kernel-Panik, Hardwarefehler
Step-by-Step Diagnostic Process
Wenn Ihr Server Probleme hat, folgen Sie diesem systematischen Ansatz:
Schritt 1: Gesamtsystemlast überprüfen
Beginnen Sie mit dem Gesamtbild mit uptime oder top:
uptime
# Ausgabe: load average: 2.50, 2.25, 2.10Der Load Average zeigt die Systemlast über 1, 5 und 15 Minuten. Zahlen höher als Ihre CPU-Anzahl zeigen an, dass das System überlastet ist. Ein 4-Kern-Server mit Load Average von 6 hat Probleme.
Schritt 2: CPU-Auslastung überprüfen
Verwenden Sie top oder htop, um CPU-hungrige Prozesse zu identifizieren:
top -cAchten Sie auf:
- Prozesse, die konstant >50% CPU verwenden
- Mehrere Instanzen desselben Prozesses
- Unbekannte Prozessnamen
Mit Überwachungstools wie MonitorVPS können Sie historische CPU-Muster sehen, um zu verstehen, ob dies ein neues Problem oder ein fortlaufender Trend ist.
Schritt 3: Speichernutzung überprüfen
free -h
# Ausgabe zeigt total, used, free, shared, buff/cache, availableWichtige Indikatoren:
- "available" ist das, was wirklich zählt, nicht "free"
- Swap-Nutzung – Hohe Swap-Nutzung bedeutet, dass Ihnen RAM ausgeht
- buff/cache – Dieser Speicher kann bei Bedarf zurückgewonnen werden
Um speicherhungrige Prozesse zu finden:
ps aux --sort=-%mem | head -20Schritt 4: Festplattenplatz überprüfen
df -h # Festplattenplatz
du -sh /* 2>/dev/null | sort -hr | head -10 # Größte VerzeichnisseHäufige Ursachen für volle Festplatten:
/var/log– Protokolldateien/tmp– Temporäre Dateien/var/lib/mysqloder/var/lib/postgresql– Datenbankdateien- Benutzer-Uploads oder Cache-Verzeichnisse
Schritt 5: Laufende Prozesse überprüfen
ps aux | wc -l # Gesamtzahl der Prozesse
ps aux --sort=-%cpu | head -20 # Top CPU-Prozesse
ps aux --sort=-%mem | head -20 # Top Speicher-ProzesseAchten Sie auf unerwartete Prozesse oder zu viele Instanzen desselben Dienstes.
Schritt 6: Systemprotokolle überprüfen
tail -100 /var/log/syslog
tail -100 /var/log/messages
journalctl -xe # Systemd-Protokolle mit ErklärungenSuchen Sie nach Fehlermeldungen, Warnungen und Mustern, die mit Ihrem Problem korrelieren.
Diagnosing Specific Problems
Meine Website ist langsam
- Prüfen Sie, ob es serverseitig oder Netzwerk ist:
curl -o /dev/null -s -w "%{time_total}\n" http://localhost - Überprüfen Sie Webserver-Fehlerprotokolle:
tail -f /var/log/nginx/error.log - Überprüfen Sie die Datenbankleistung: Slow-Query-Logs, Verbindungszahlen
- Überprüfen Sie PHP/Anwendungsprotokolle auf Fehler
- Überwachen Sie die Ressourcennutzung während langsamer Perioden
Datenbank ist langsam
- Suchen Sie nach lang laufenden Abfragen:
SHOW PROCESSLIST;in MySQL - Überprüfen Sie das Slow-Query-Log
- Überprüfen Sie den Festplattenplatz (Datenbanken brauchen Platz für temporäre Tabellen)
- Überprüfen Sie den Speicher – swappt die Datenbank?
- Achten Sie auf Verbindungslimits, die erreicht werden
Server abgestürzt/unerwartet neu gestartet
- Überprüfen Sie
/var/log/kern.logauf Kernel-Meldungen - Suchen Sie nach OOM-Killer-Aktivität:
grep -i "killed process" /var/log/kern.log - Überprüfen Sie
last rebootfür die Neustart-Historie - Überprüfen Sie die Meldungen vor dem Absturz in
/var/log/syslog
Kann nicht per SSH auf den Server zugreifen
- Prüfen Sie, ob der Server erreichbar ist: Ping oder Web-Interface
- Versuchen Sie den Konsolenzugang über Ihren Hosting-Anbieter
- Prüfen Sie, ob der SSH-Dienst läuft:
systemctl status sshd - Prüfen Sie, ob die Firewall blockiert:
iptables -L -n - Überprüfen Sie SSH-Protokolle:
/var/log/auth.log
Using Monitoring for Proactive Diagnosis
Reaktive Fehlerbehebung ist stressig. Proaktive Überwachung ist besser:
- Baseline Ihres Servers erstellen – Normale Ressourcennutzungsmuster verstehen
- Alarmschwellen setzen – Benachrichtigt werden, bevor Probleme kritisch werden
- Historische Daten nutzen – Aktuelle Metriken mit vergangener Leistung vergleichen
- Anomalieerkennung aktivieren – Das System ungewöhnliche Muster identifizieren lassen
- Prozesse überwachen – Wissen, was läuft und wie viel es verbraucht
Tools wie MonitorVPS bieten diese Sichtbarkeit ohne komplexes Setup. Sie erhalten kontinuierliche Überwachung mit Warnungen, wenn etwas schief geht, was die Diagnose viel schneller macht, weil Sie bereits die Daten haben.
Prevention: Reducing Future Problems
Viele Serverprobleme können verhindert werden:
- Server richtig dimensionieren – Nicht normalerweise bei 90% Kapazität laufen
- Protokollrotation einrichten – Verhindern, dass Protokolldateien Festplatten füllen
- Festplattentrends überwachen – Wachstum adressieren, bevor es kritisch wird
- Software aktuell halten – Patches beheben Bugs und Sicherheitsprobleme
- Traffic-Spitzen planen – Ihre Grenzen kennen und Skalierungsstrategien haben
- Regelmäßige Gesundheitschecks – Nicht auf Probleme warten, um Ihre Server zu überprüfen
Conclusion
Serverprobleme sind unvermeidlich, aber sie müssen keine Krisen sein. Mit systematischer Diagnose und proaktiver Überwachung können Sie Probleme schnell identifizieren und lösen. Der Schlüssel ist die Sichtbarkeit des Verhaltens Ihres Servers – sowohl aktuell als auch historisch.
Beginnen Sie mit den Grundlagen: CPU, Speicher, Festplatte. Überprüfen Sie Prozesse und Protokolle. Verwenden Sie Überwachungstools, um Baselines zu erstellen und Probleme frühzeitig zu erkennen. Mit Übung und guten Tools wird die Diagnose von Serverproblemen zur Routine statt zum Stress.