Diagnóstico de problemas comunes en servidores VPS
Una guía práctica para solucionar problemas de servidores VPS. Aprende a diagnosticar y resolver sistemáticamente cuellos de botella de rendimiento.
Diagnosticar problemas de servidor VPS implica verificar sistemáticamente la utilización de recursos (CPU, memoria, disco), analizar procesos en ejecución, revisar logs y usar herramientas de monitorización para identificar patrones. La mayoría de los problemas del servidor caen en unas pocas categorías comunes que pueden identificarse rápidamente con el enfoque correcto.
Common VPS Server Problems and Their Symptoms
Antes de adentrarnos en el diagnóstico, entender los patrones de problemas comunes te ayuda a identificar problemas más rápido:
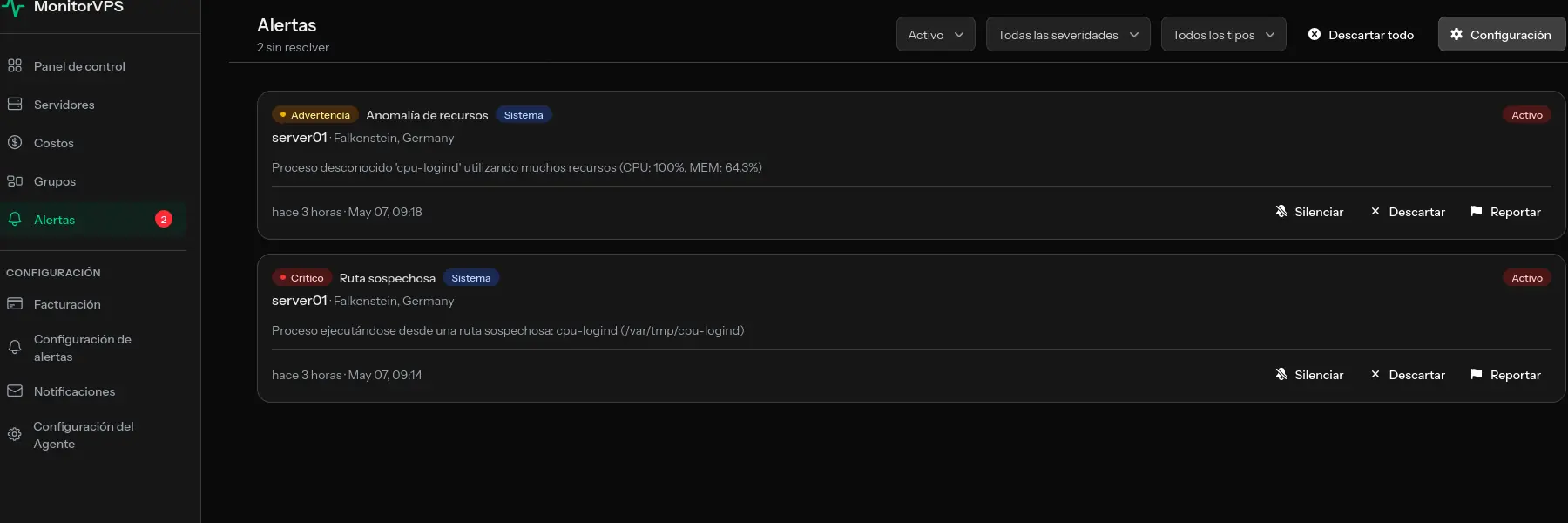
Alto Uso de CPU
- Síntomas: Tiempos de respuesta lentos, errores de timeout, alto load average
- Causas comunes: Procesos descontrolados, picos de tráfico, código ineficiente, malware
Agotamiento de Memoria
- Síntomas: Aplicaciones que se bloquean, OOM killer terminando procesos, pico en uso de swap
- Causas comunes: Fugas de memoria, RAM insuficiente, demasiadas conexiones concurrentes
Problemas de Espacio en Disco
- Síntomas: Fallos de escritura, errores de base de datos, bloqueos de aplicación, fallos de rotación de logs
- Causas comunes: Crecimiento de archivos de log, caché sin limpiar, inflación de base de datos, uploads de archivos
Servidor Sin Respuesta
- Síntomas: Timeout de SSH, solicitudes web fallando, servicios sin responder
- Causas comunes: Agotamiento de recursos, problemas de red, kernel panic, fallo de hardware
Step-by-Step Diagnostic Process
Cuando tu servidor tiene problemas, sigue este enfoque sistemático:
Paso 1: Verificar la Carga General del Sistema
Comienza con el panorama general usando uptime o top:
uptime
# Salida: load average: 2.50, 2.25, 2.10El load average muestra la carga del sistema durante 1, 5 y 15 minutos. Números más altos que el conteo de CPU indican que el sistema está sobrecargado. Un servidor de 4 núcleos con load average de 6 está luchando.
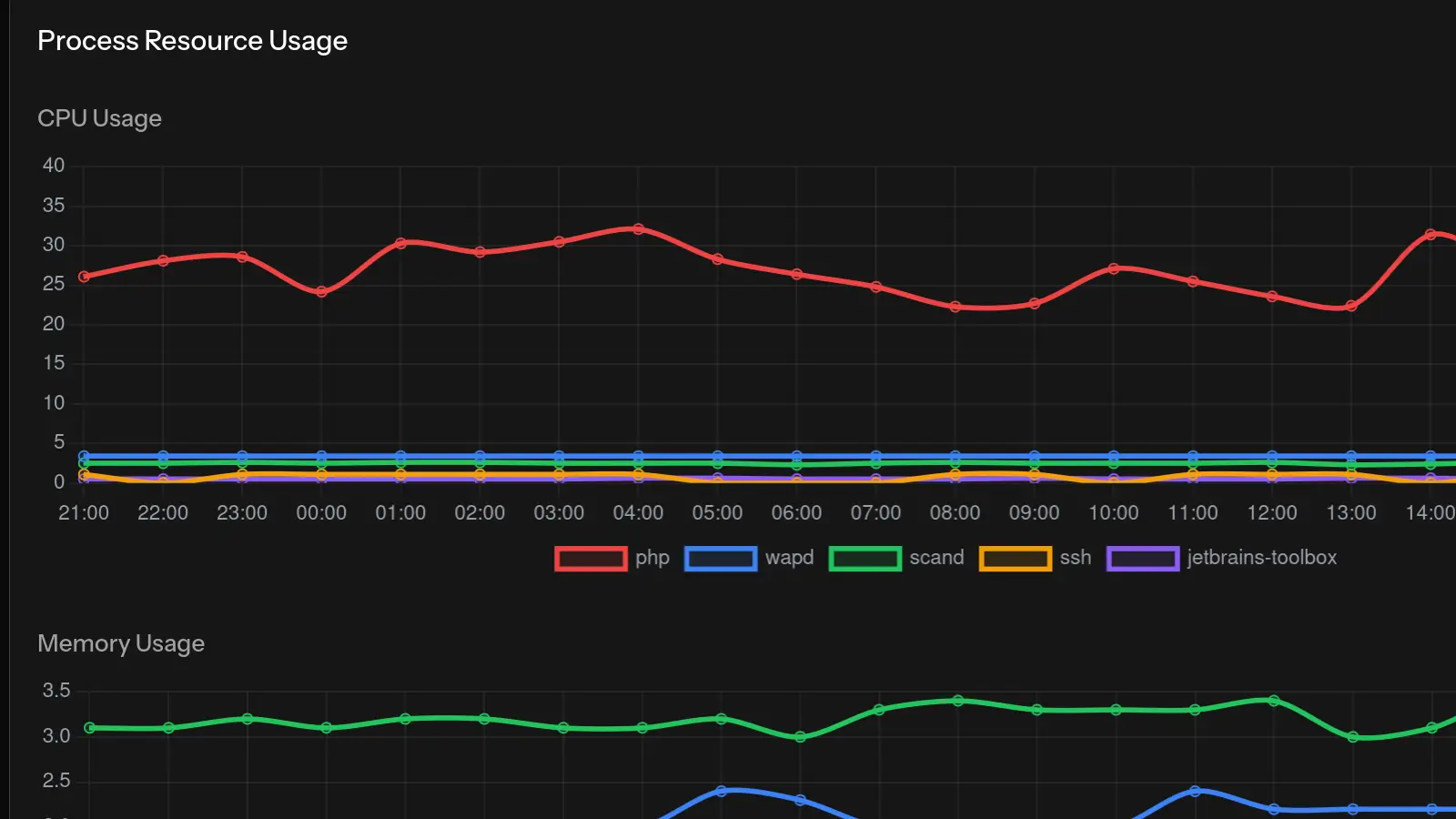
Paso 2: Verificar Uso de CPU
Usa top o htop para identificar procesos que consumen CPU:
top -cBusca:
- Procesos usando >50% de CPU consistentemente
- Múltiples instancias del mismo proceso
- Nombres de procesos desconocidos
Con herramientas de monitorización como MonitorVPS, puedes ver patrones históricos de CPU para entender si esto es un problema nuevo o una tendencia continua.
Paso 3: Verificar Uso de Memoria
free -h
# La salida muestra total, used, free, shared, buff/cache, availableIndicadores clave:
- "available" es lo que realmente importa, no "free"
- Uso de Swap – Alto uso de swap significa que te estás quedando sin RAM
- buff/cache – Esta memoria puede reclamarse si es necesario
Para encontrar procesos que consumen memoria:
ps aux --sort=-%mem | head -20Paso 4: Verificar Espacio en Disco
df -h # Espacio en disco
du -sh /* 2>/dev/null | sort -hr | head -10 # Directorios más grandesCausantes comunes de discos llenos:
/var/log– Archivos de log/tmp– Archivos temporales/var/lib/mysqlo/var/lib/postgresql– Archivos de base de datos- Uploads de usuarios o directorios de caché
Paso 5: Verificar Procesos en Ejecución
ps aux | wc -l # Conteo total de procesos
ps aux --sort=-%cpu | head -20 # Procesos con más CPU
ps aux --sort=-%mem | head -20 # Procesos con más memoriaBusca procesos inesperados o demasiadas instancias del mismo servicio.
Paso 6: Revisar Logs del Sistema
tail -100 /var/log/syslog
tail -100 /var/log/messages
journalctl -xe # Logs de Systemd con explicacionesBusca mensajes de error, advertencias y patrones que correlacionen con tu problema.
Diagnosing Specific Problems
Mi sitio web está lento
- Verifica si es del servidor o de la red:
curl -o /dev/null -s -w "%{time_total}\n" http://localhost - Revisa logs de error del servidor web:
tail -f /var/log/nginx/error.log - Verifica el rendimiento de la base de datos: logs de consultas lentas, conteo de conexiones
- Revisa logs de PHP/aplicación en busca de errores
- Monitoriza el uso de recursos durante períodos lentos
La base de datos está lenta
- Busca consultas de larga duración:
SHOW PROCESSLIST;en MySQL - Revisa el log de consultas lentas
- Verifica el espacio en disco (las bases de datos necesitan espacio para tablas temporales)
- Verifica la memoria—¿está la base de datos usando swap?
- Busca límites de conexión que se estén alcanzando
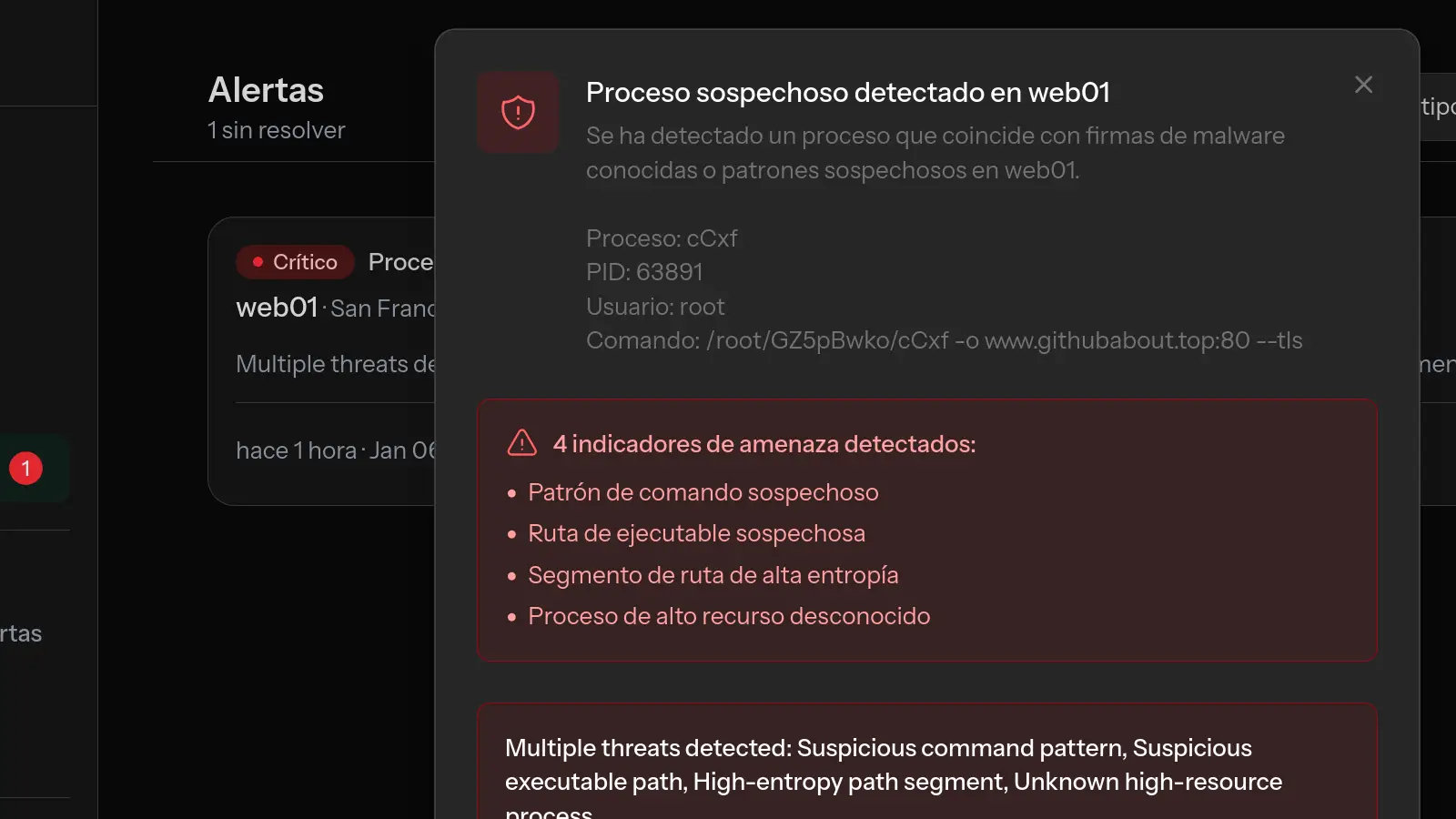
El servidor se bloqueó/reinició inesperadamente
- Revisa
/var/log/kern.logpara mensajes del kernel - Busca actividad del OOM killer:
grep -i "killed process" /var/log/kern.log - Revisa
last rebootpara el historial de reinicios - Revisa los mensajes previos al bloqueo en
/var/log/syslog
No puedo conectar por SSH al servidor
- Verifica si el servidor es alcanzable: ping, o interfaz web
- Intenta acceso por consola a través de tu proveedor de hosting
- Verifica si el servicio SSH está corriendo:
systemctl status sshd - Verifica si el firewall está bloqueando:
iptables -L -n - Revisa logs de SSH:
/var/log/auth.log
Using Monitoring for Proactive Diagnosis
La resolución de problemas reactiva es estresante. La monitorización proactiva es mejor:
- Establece una línea base de tu servidor – Entiende los patrones normales de uso de recursos
- Configura umbrales de alerta – Recibe notificaciones antes de que los problemas se vuelvan críticos
- Usa datos históricos – Compara métricas actuales con el rendimiento pasado
- Habilita detección de anomalías – Deja que el sistema identifique patrones inusuales
- Monitoriza procesos – Sabe qué está corriendo y cuánto consume
Herramientas como MonitorVPS proporcionan esta visibilidad sin configuración compleja. Obtienes monitorización continua con alertas cuando algo sale mal, haciendo el diagnóstico mucho más rápido porque ya tienes los datos.
Prevention: Reducing Future Problems
Muchos problemas del servidor pueden prevenirse:
- Dimensiona correctamente tu servidor – No operes normalmente al 90% de capacidad
- Configura rotación de logs – Previene que los archivos de log llenen los discos
- Monitoriza tendencias de disco – Aborda el crecimiento antes de que se vuelva crítico
- Mantén el software actualizado – Los parches corrigen bugs y problemas de seguridad
- Planifica para picos de tráfico – Conoce tus límites y ten estrategias de escalado
- Chequeos de salud regulares – No esperes problemas para revisar tus servidores
Conclusion
Los problemas del servidor son inevitables, pero no tienen que ser crisis. Con diagnóstico sistemático y monitorización proactiva, puedes identificar y resolver problemas rápidamente. La clave es tener visibilidad del comportamiento de tu servidor—tanto actual como histórico.
Comienza con lo básico: CPU, memoria, disco. Revisa procesos y logs. Usa herramientas de monitorización para establecer líneas base y detectar problemas temprano. Con práctica y buenas herramientas, diagnosticar problemas del servidor se convierte en rutina en lugar de estrés.