Diagnose van veelvoorkomende VPS-serverproblemen
Een praktische gids voor het oplossen van VPS-serverproblemen. Leer systematisch prestatieproblemen te diagnosticeren en op te lossen.
Het diagnosticeren van VPS-serverproblemen omvat het systematisch controleren van resourcegebruik (CPU, geheugen, schijf), het analyseren van draaiende processen, het bekijken van logs en het gebruik van monitoringtools om patronen te identificeren. De meeste serverproblemen vallen in een paar veelvoorkomende categorieën die snel kunnen worden geïdentificeerd met de juiste aanpak.
Common VPS Server Problems and Their Symptoms
Voordat we in diagnose duiken, helpt het begrijpen van veelvoorkomende probleempatronen je problemen sneller te identificeren:
Hoog CPU-gebruik
- Symptomen: Trage responstijden, timeout-fouten, hoge load average
- Veelvoorkomende oorzaken: Ontspoorde processen, verkeerspieken, inefficiënte code, malware
Geheugenuitputting
- Symptomen: Crashende applicaties, OOM killer die processen beëindigt, swap-gebruikspiek
- Veelvoorkomende oorzaken: Geheugenlekken, onvoldoende RAM, te veel gelijktijdige verbindingen
Schijfruimteproblemen
- Symptomen: Schrijffouten, databasefouten, applicatiecrashes, logrotatiemislukkingen
- Veelvoorkomende oorzaken: Groei van logbestanden, niet-gewiste cache, database-opzwelling, bestandsuploads
Niet-reagerende Server
- Symptomen: SSH-timeout, falende webverzoeken, diensten die niet reageren
- Veelvoorkomende oorzaken: Resourceuitputting, netwerkproblemen, kernel panic, hardwarefalen
Step-by-Step Diagnostic Process
Wanneer je server problemen heeft, volg dan deze systematische aanpak:
Stap 1: Controleer Algehele Systeembelasting
Begin met het grote geheel met uptime of top:
uptime
# Output: load average: 2.50, 2.25, 2.10Load average toont systeembelasting over 1, 5 en 15 minuten. Getallen hoger dan je CPU-aantal geven aan dat het systeem overbelast is. Een 4-core server met load average van 6 heeft problemen.
Stap 2: Controleer CPU-gebruik
Gebruik top of htop om CPU-hongerende processen te identificeren:
top -cLet op:
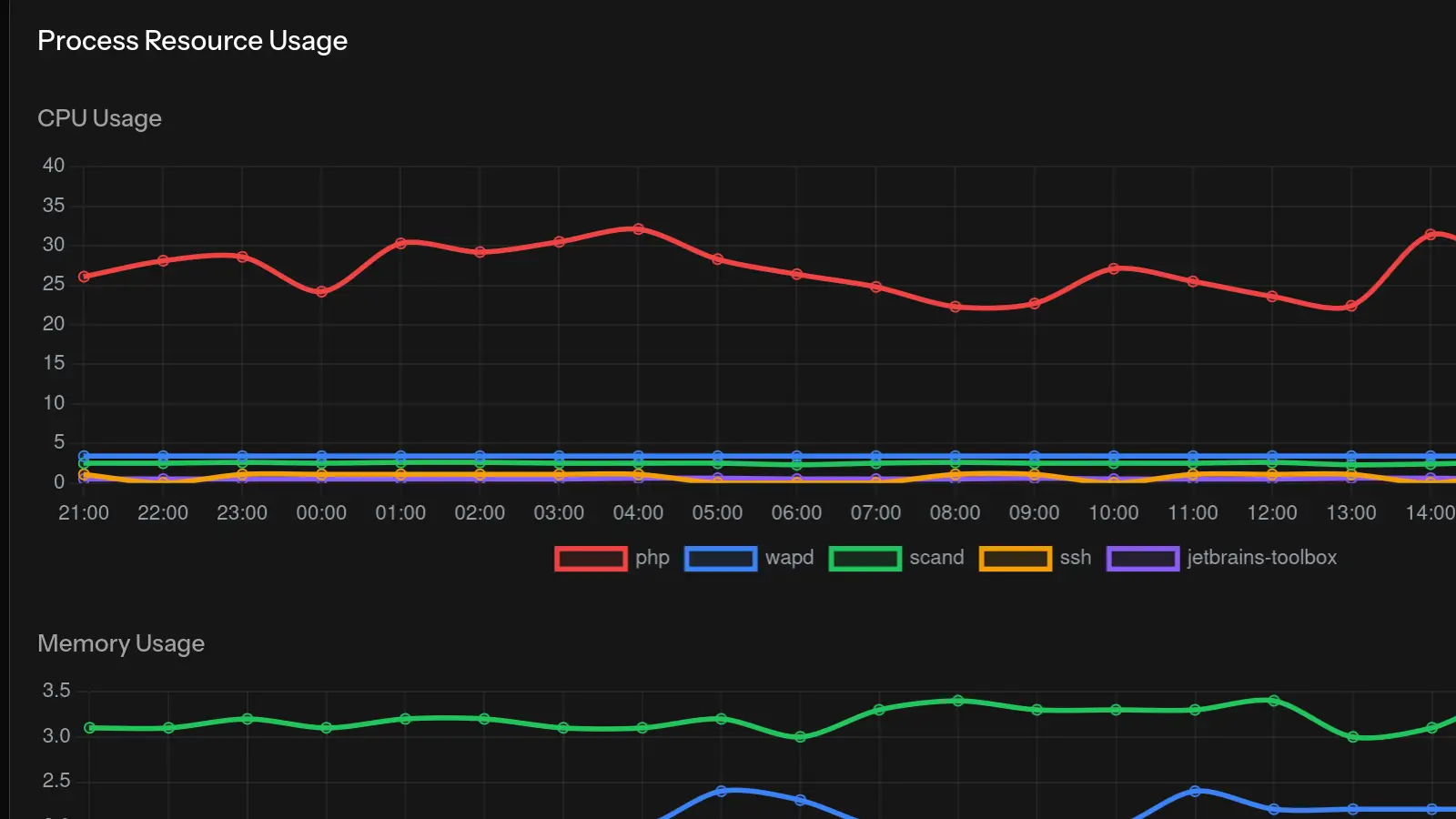
- Processen die consistent >50% CPU gebruiken
- Meerdere instanties van hetzelfde proces
- Onbekende procesnamen
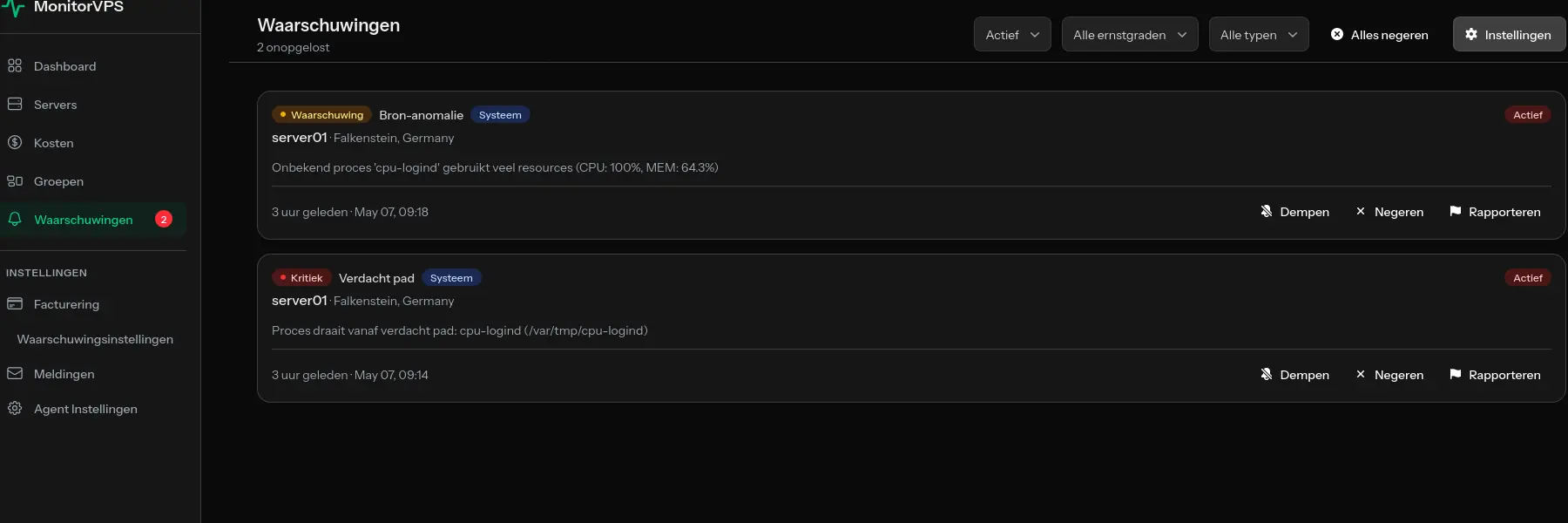
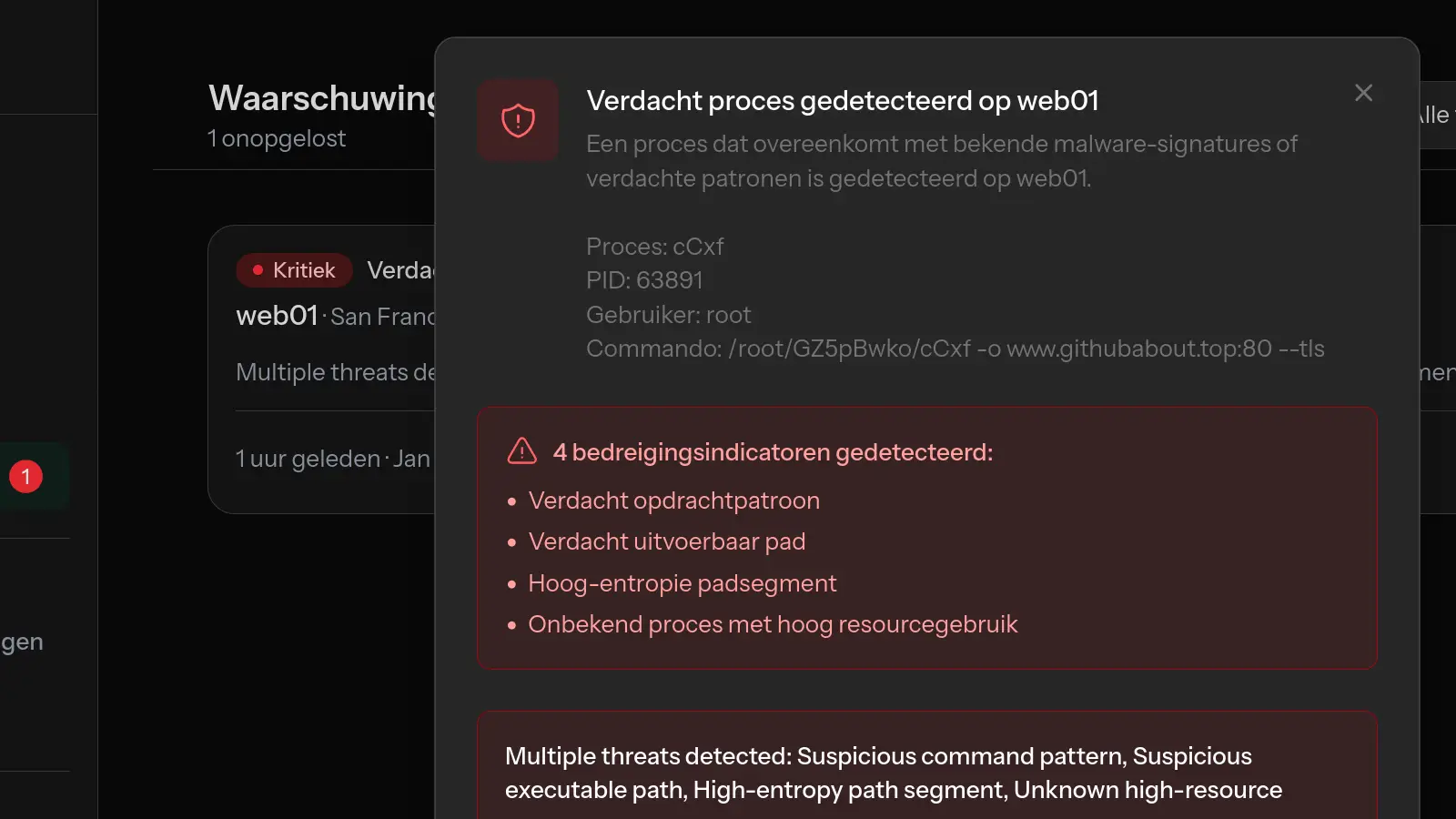
Met monitoringtools zoals MonitorVPS kun je historische CPU-patronen zien om te begrijpen of dit een nieuw probleem of een doorlopende trend is.
Stap 3: Controleer Geheugengebruik
free -h
# Output toont total, used, free, shared, buff/cache, availableBelangrijke indicatoren:
- "available" is wat er echt toe doet, niet "free"
- Swap-gebruik – Hoog swap-gebruik betekent dat je RAM opraakt
- buff/cache – Dit geheugen kan worden teruggewonnen indien nodig
Om geheugen-hongerende processen te vinden:
ps aux --sort=-%mem | head -20Stap 4: Controleer Schijfruimte
df -h # Schijfruimte
du -sh /* 2>/dev/null | sort -hr | head -10 # Grootste mappenVeelvoorkomende boosdoeners voor volle schijven:
/var/log– Logbestanden/tmp– Tijdelijke bestanden/var/lib/mysqlof/var/lib/postgresql– Databasebestanden- Gebruikersuploads of cachemappen
Stap 5: Controleer Draaiende Processen
ps aux | wc -l # Totaal aantal processen
ps aux --sort=-%cpu | head -20 # Top CPU-processen
ps aux --sort=-%mem | head -20 # Top geheugen-processenZoek naar onverwachte processen of te veel instanties van dezelfde dienst.
Stap 6: Bekijk Systeemlogs
tail -100 /var/log/syslog
tail -100 /var/log/messages
journalctl -xe # Systemd-logs met uitlegZoek naar foutmeldingen, waarschuwingen en patronen die correleren met je probleem.
Diagnosing Specific Problems
Mijn website is traag
- Controleer of het server-side of netwerk is:
curl -o /dev/null -s -w "%{time_total}\n" http://localhost - Controleer webserver-errorlogs:
tail -f /var/log/nginx/error.log - Controleer databaseprestaties: slow query logs, verbindingsaantallen
- Controleer PHP/applicatielogs op fouten
- Monitor resourcegebruik tijdens trage periodes
Database is traag
- Zoek naar langlopende queries:
SHOW PROCESSLIST;in MySQL - Bekijk slow query log
- Controleer schijfruimte (databases hebben ruimte nodig voor tijdelijke tabellen)
- Controleer geheugen—swapt de database?
- Kijk of verbindingslimieten worden bereikt
Server gecrasht/onverwacht herstart
- Controleer
/var/log/kern.logvoor kernelberichten - Zoek naar OOM killer-activiteit:
grep -i "killed process" /var/log/kern.log - Controleer
last rebootvoor herstartgeschiedenis - Bekijk berichten voorafgaand aan de crash in
/var/log/syslog
Kan niet SSH'en naar Server
- Controleer of server bereikbaar is: ping, of webinterface
- Probeer consoletoegang via je hostingprovider
- Controleer of SSH-service draait:
systemctl status sshd - Controleer of firewall blokkeert:
iptables -L -n - Controleer SSH-logs:
/var/log/auth.log
Using Monitoring for Proactive Diagnosis
Reactieve probleemoplossing is stressvol. Proactieve monitoring is beter:
- Baseline je server – Begrijp normale resourcegebruikspatronen
- Stel waarschuwingsdrempels in – Word gewaarschuwd voordat problemen kritiek worden
- Gebruik historische gegevens – Vergelijk huidige metrieken met prestaties uit het verleden
- Schakel anomaliedetectie in – Laat het systeem ongebruikelijke patronen identificeren
- Monitor processen – Weet wat er draait en hoeveel het verbruikt
Tools zoals MonitorVPS bieden deze zichtbaarheid zonder complexe setup. Je krijgt continue monitoring met waarschuwingen wanneer dingen misgaan, waardoor diagnose veel sneller is omdat je de gegevens al hebt.
Prevention: Reducing Future Problems
Veel serverproblemen kunnen worden voorkomen:
- Dimensioneer je server juist – Draai niet normaal op 90% capaciteit
- Stel logrotatie in – Voorkom dat logbestanden schijven vullen
- Monitor schijftrends – Pak groei aan voordat het kritiek wordt
- Houd software bijgewerkt – Patches lossen bugs en beveiligingsproblemen op
- Plan voor verkeerspieken – Ken je limieten en heb schaalstrategieën
- Regelmatige gezondheidscontroles – Wacht niet op problemen om je servers te bekijken
Conclusion
Serverproblemen zijn onvermijdelijk, maar ze hoeven geen crises te zijn. Met systematische diagnose en proactieve monitoring kun je problemen snel identificeren en oplossen. De sleutel is zichtbaarheid in het gedrag van je server—zowel huidig als historisch.
Begin met de basis: CPU, geheugen, schijf. Controleer processen en logs. Gebruik monitoringtools om baselines te vestigen en problemen vroeg te detecteren. Met oefening en goede tooling wordt het diagnosticeren van serverproblemen routine in plaats van stress.