Diagnostic des problèmes courants de serveur VPS
Un guide pratique pour résoudre les problèmes de serveur VPS. Apprenez à diagnostiquer et résoudre systématiquement les goulots d'étranglement de performance.
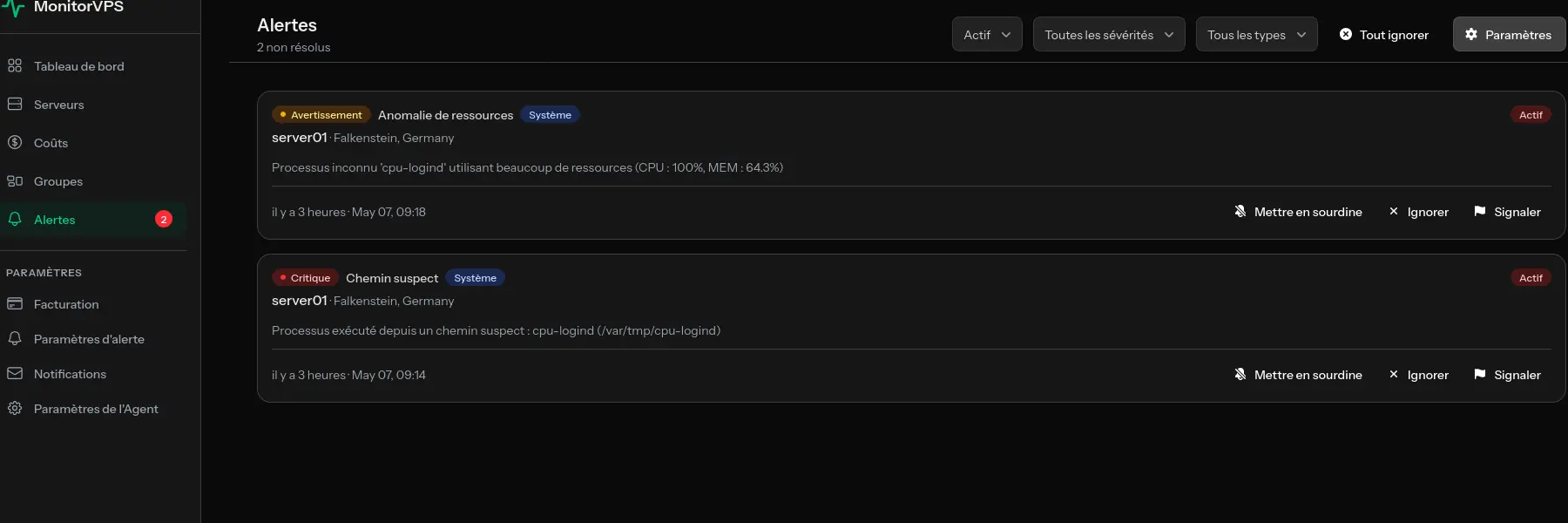
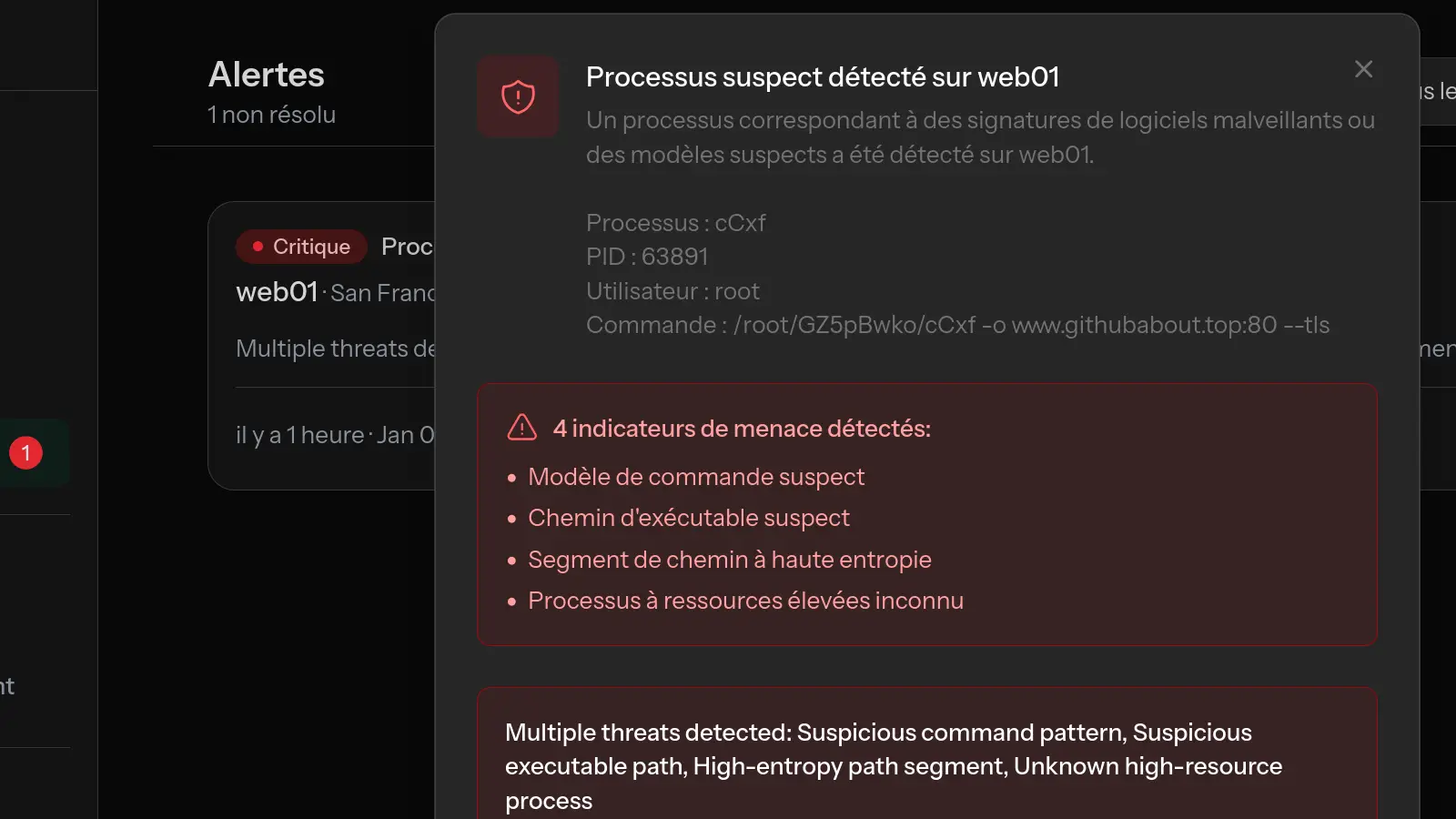
Le diagnostic des problèmes de serveur VPS implique la vérification systématique de l'utilisation des ressources (CPU, mémoire, disque), l'analyse des processus en cours d'exécution, l'examen des journaux et l'utilisation d'outils de surveillance pour identifier les schémas. La plupart des problèmes de serveur tombent dans quelques catégories courantes qui peuvent être rapidement identifiées avec la bonne approche.
Common VPS Server Problems and Their Symptoms
Avant de plonger dans le diagnostic, comprendre les schémas de problèmes courants vous aide à identifier les problèmes plus rapidement :
Utilisation CPU Élevée
- Symptômes : Temps de réponse lents, erreurs de timeout, load average élevé
- Causes courantes : Processus incontrôlés, pics de trafic, code inefficace, malware
Épuisement de la Mémoire
- Symptômes : Applications qui plantent, OOM killer terminant des processus, pic d'utilisation du swap
- Causes courantes : Fuites de mémoire, RAM insuffisante, trop de connexions simultanées
Problèmes d'Espace Disque
- Symptômes : Échecs d'écriture, erreurs de base de données, plantages d'applications, échecs de rotation des journaux
- Causes courantes : Croissance des fichiers journaux, cache non vidé, gonflement de base de données, téléchargements de fichiers
Serveur Non Réactif
- Symptômes : Timeout SSH, requêtes web échouant, services ne répondant pas
- Causes courantes : Épuisement des ressources, problèmes réseau, kernel panic, panne matérielle
Step-by-Step Diagnostic Process
Lorsque votre serveur a des problèmes, suivez cette approche systématique :
Étape 1 : Vérifier la Charge Globale du Système
Commencez par la vue d'ensemble en utilisant uptime ou top :
uptime
# Sortie : load average: 2.50, 2.25, 2.10Le load average montre la charge du système sur 1, 5 et 15 minutes. Des nombres supérieurs à votre nombre de CPU indiquent que le système est surchargé. Un serveur à 4 cœurs avec un load average de 6 est en difficulté.
Étape 2 : Vérifier l'Utilisation CPU
Utilisez top ou htop pour identifier les processus gourmands en CPU :
top -cRecherchez :
- Processus utilisant >50% de CPU de manière constante
- Plusieurs instances du même processus
- Noms de processus inconnus
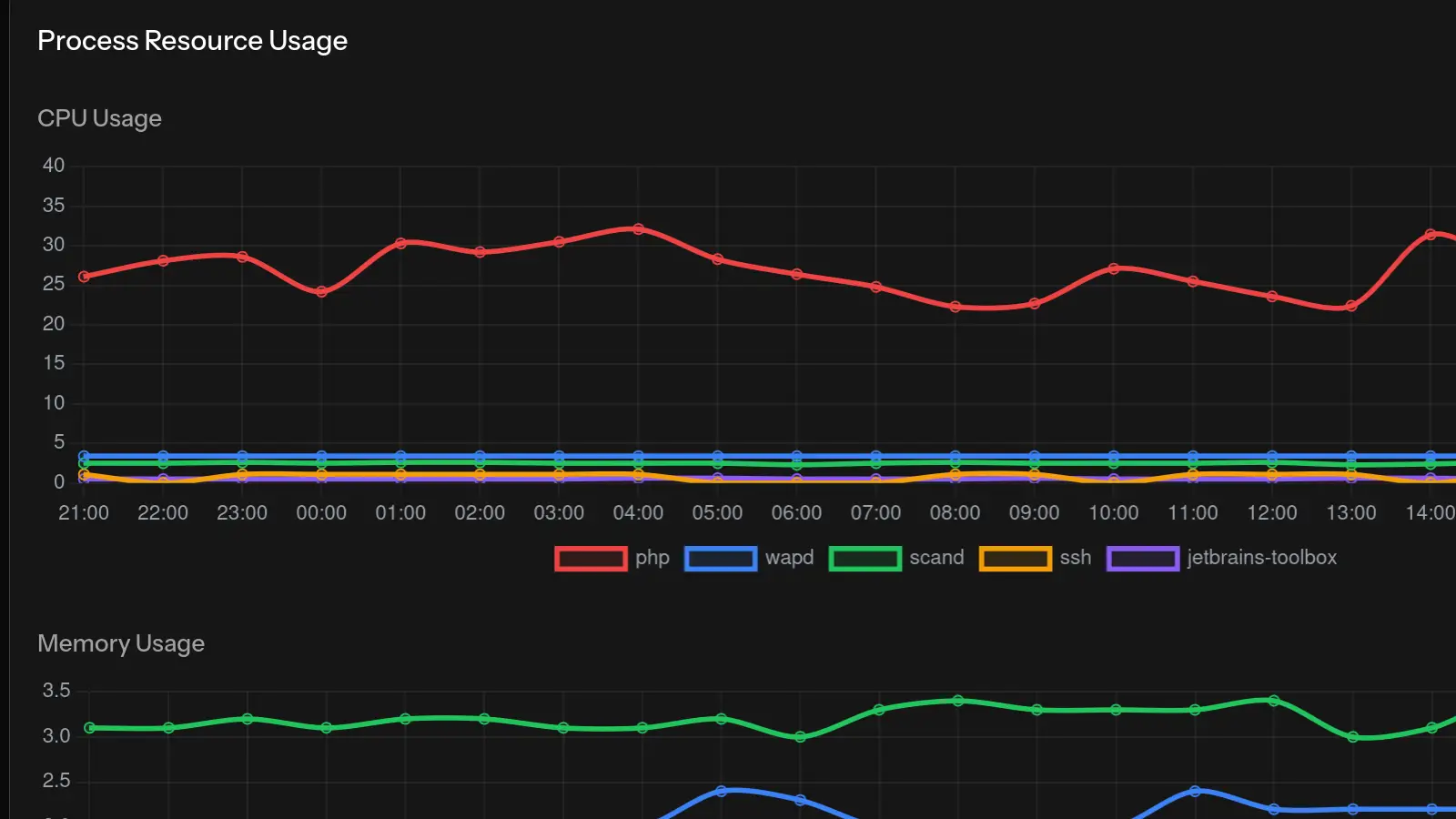
Avec des outils de surveillance comme MonitorVPS, vous pouvez voir les schémas historiques de CPU pour comprendre si c'est un nouveau problème ou une tendance continue.
Étape 3 : Vérifier l'Utilisation de la Mémoire
free -h
# La sortie montre total, used, free, shared, buff/cache, availableIndicateurs clés :
- "available" est ce qui compte vraiment, pas "free"
- Utilisation du Swap – Une utilisation élevée du swap signifie que vous manquez de RAM
- buff/cache – Cette mémoire peut être récupérée si nécessaire
Pour trouver les processus gourmands en mémoire :
ps aux --sort=-%mem | head -20Étape 4 : Vérifier l'Espace Disque
df -h # Espace disque
du -sh /* 2>/dev/null | sort -hr | head -10 # Plus grands répertoiresCoupables courants des disques pleins :
/var/log– Fichiers journaux/tmp– Fichiers temporaires/var/lib/mysqlou/var/lib/postgresql– Fichiers de base de données- Téléchargements utilisateurs ou répertoires de cache
Étape 5 : Vérifier les Processus en Cours
ps aux | wc -l # Nombre total de processus
ps aux --sort=-%cpu | head -20 # Processus top CPU
ps aux --sort=-%mem | head -20 # Processus top mémoireRecherchez les processus inattendus ou trop d'instances du même service.
Étape 6 : Examiner les Journaux Système
tail -100 /var/log/syslog
tail -100 /var/log/messages
journalctl -xe # Journaux Systemd avec explicationsRecherchez les messages d'erreur, les avertissements et les schémas qui corrèlent avec votre problème.
Diagnosing Specific Problems
Mon site web est lent
- Vérifiez si c'est côté serveur ou réseau :
curl -o /dev/null -s -w "%{time_total}\n" http://localhost - Vérifiez les journaux d'erreur du serveur web :
tail -f /var/log/nginx/error.log - Vérifiez les performances de la base de données : journaux de requêtes lentes, nombre de connexions
- Vérifiez les journaux PHP/application pour les erreurs
- Surveillez l'utilisation des ressources pendant les périodes lentes
La base de données est lente
- Recherchez les requêtes longues :
SHOW PROCESSLIST;dans MySQL - Examinez le journal des requêtes lentes
- Vérifiez l'espace disque (les bases de données ont besoin d'espace pour les tables temporaires)
- Vérifiez la mémoire — la base de données utilise-t-elle le swap ?
- Recherchez les limites de connexion atteintes
Le serveur a planté/redémarré de manière inattendue
- Vérifiez
/var/log/kern.logpour les messages du kernel - Recherchez l'activité du OOM killer :
grep -i "killed process" /var/log/kern.log - Vérifiez
last rebootpour l'historique des redémarrages - Examinez les messages précédant le plantage dans
/var/log/syslog
Impossible de se connecter en SSH au serveur
- Vérifiez si le serveur est accessible : ping, ou interface web
- Essayez l'accès console via votre hébergeur
- Vérifiez si le service SSH est en cours d'exécution :
systemctl status sshd - Vérifiez si le pare-feu bloque :
iptables -L -n - Vérifiez les journaux SSH :
/var/log/auth.log
Using Monitoring for Proactive Diagnosis
Le dépannage réactif est stressant. La surveillance proactive est meilleure :
- Établir une baseline de votre serveur – Comprendre les schémas normaux d'utilisation des ressources
- Définir des seuils d'alerte – Être notifié avant que les problèmes ne deviennent critiques
- Utiliser les données historiques – Comparer les métriques actuelles aux performances passées
- Activer la détection d'anomalies – Laisser le système identifier les schémas inhabituels
- Surveiller les processus – Savoir ce qui tourne et combien cela consomme
Des outils comme MonitorVPS offrent cette visibilité sans configuration complexe. Vous obtenez une surveillance continue avec des alertes quand quelque chose ne va pas, rendant le diagnostic beaucoup plus rapide car vous avez déjà les données.
Prevention: Reducing Future Problems
De nombreux problèmes de serveur peuvent être évités :
- Dimensionner correctement votre serveur – Ne pas fonctionner normalement à 90% de capacité
- Configurer la rotation des journaux – Empêcher les fichiers journaux de remplir les disques
- Surveiller les tendances de disque – Traiter la croissance avant qu'elle ne devienne critique
- Maintenir le logiciel à jour – Les correctifs corrigent les bugs et les problèmes de sécurité
- Planifier les pics de trafic – Connaître vos limites et avoir des stratégies de mise à l'échelle
- Vérifications de santé régulières – Ne pas attendre les problèmes pour examiner vos serveurs
Conclusion
Les problèmes de serveur sont inévitables, mais ils n'ont pas besoin d'être des crises. Avec un diagnostic systématique et une surveillance proactive, vous pouvez identifier et résoudre les problèmes rapidement. La clé est d'avoir une visibilité sur le comportement de votre serveur — actuel et historique.
Commencez par les bases : CPU, mémoire, disque. Vérifiez les processus et les journaux. Utilisez des outils de surveillance pour établir des baselines et détecter les problèmes tôt. Avec de la pratique et de bons outils, diagnostiquer les problèmes de serveur devient une routine plutôt qu'un stress.